Building a semantic layer in a data warehouse project requires twice the work required to build a pipeline management system and a data lake. As a result, many clients decide to skip this step at the outset of their data warehouse project.
We think making data easy to access —the logistics problems—is a problem worth solving alone. Co-locating your data and making it easy to move around creates enormous value for your organization.
A semantic layer will eventually evolve out of a data lake, especially if the layer can be fed with new data sources. And as a data lake’s users get better at using data for sponsors, they’ll figure out how to connect the dots across different domains and sources. However, that evolution can’t happen without easy logistics, so building a basic data warehouse is the right first step.
Eventually, to maximize the value of your data, you’ll need to do some intentional organization or data modeling. While the effort is significant, we think it’s possible to do just the right amount of data modeling to build your semantic layer. This insight will discuss how we do that at DEPT®.
The problem
Let’s frame the problem.
We often talk to sponsors that want a data warehouse because:
- There are no backups for the people who hold everything together.
- No one knows for sure what data is in “the data warehouse,” including the data warehouse manager.
- Reporting is inconsistent or just plain wrong.
- The data model is patched together and hard to use and everyone knows it’s dated.
These are largely problems with their current semantic layer.
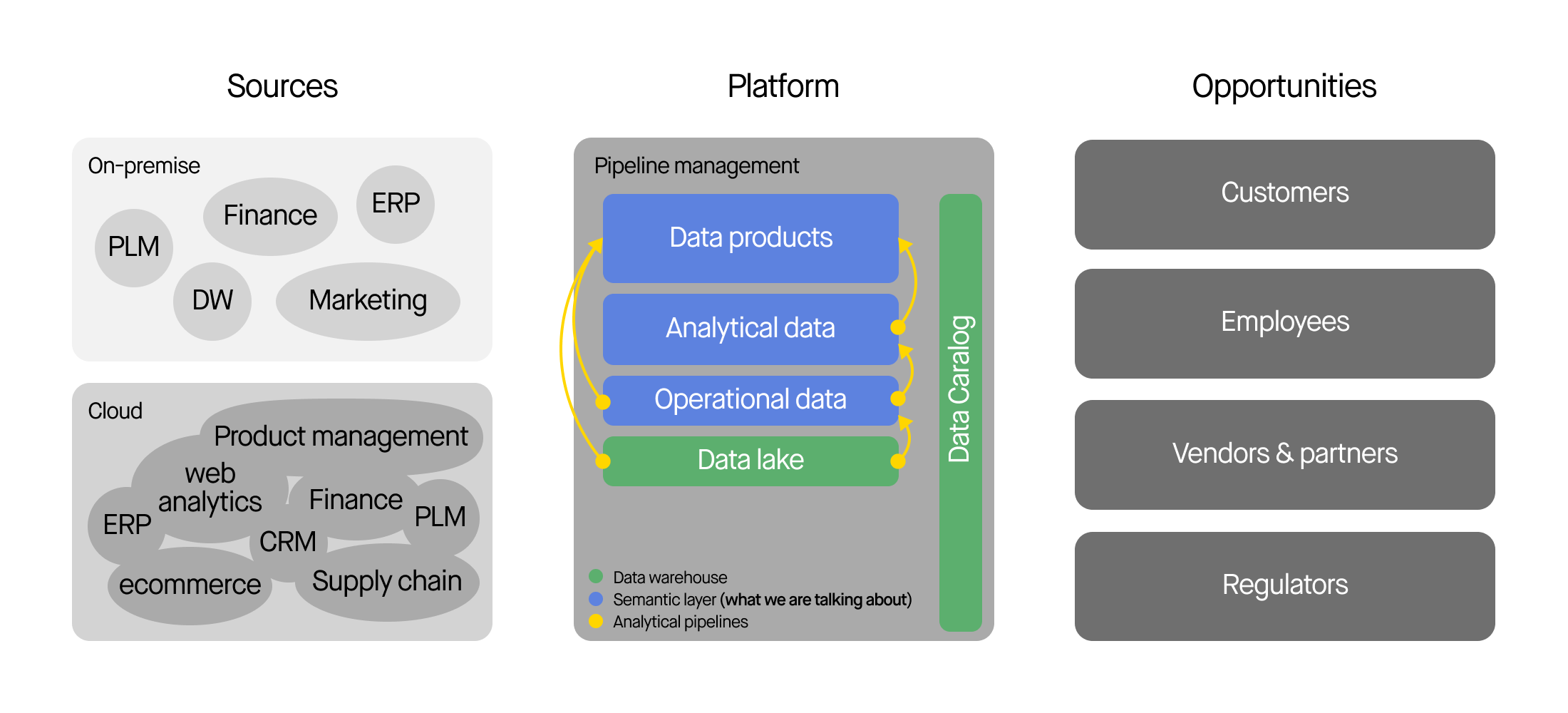
Every organization’s reporting is squeezed out of its actual semantic layer. A semantic layer has two components:
- An organic mix of data models (and data) from different source systems: ERPs, product catalogs, call center and marketing systems, a financial data warehouse or FP&A system, web analytics vendors, and home-grown applications.
- The SQL, software code and reporting business logic that holds together those data models and the dashboards the executives see.
Often these two components are held together by word of mouth: Priya knows where 17 sources of customer data are, and Sam knows 5, and luckily Sam and Priya know each other. Parts of the semantic layer may be inconsistent, and organic change has usually left it less than organized.
Most sponsors want a good semantic layer to go along with their new data warehouse, because a semantic layer with inconsistent or obscure data is often worse than nothing at all. Moreover, Sam and Priya represent a significant “lottery risk,” and everyone wants to write easy queries too. A good semantic layer reduces those risks.
But good semantic layers are rare, and as I mentioned at the top, we at DEPT® are clear with our clients that this particular part of the business is the harder chunk of work. Why is it so hard to create a good semantic layer?
Why is it hard to solve this problem?
On a new data warehouse project, new data models may solve at least one of the problems above. People might at some point even say it was a success. The first batch of new reports usually work too, but with the simplest possible available data.
Coworkers will tell the sponsor the model has some weird edges:
- Inconsistent naming conventions where different teams worked on different domains.
- Limited ability to organize all of the data they have available to them.
- Some odd spots in the diagram where the model doesn’t seem to work or just seems a little hand-wavey.
- The data modelers appear to be the only ones who understand the model.
Sponsors can hopefully get the modeling team to put that feedback onto their backlog. But as these are often among the problems teams had with their last data warehouse data model, there’s bound to be some disappointment.
But the modeling team also has a deadline. The model theoretically needs to be done, as in done-finished-done, before people can build reports. It’s likely that once the “final” model is published and posted in everyone’s cubes the model is already critically out of date, having failed some processes it needed to support, just because the modeling team ran out of time. By the end of “phase one,” people are already complaining they can’t get the data they need and will just go back to the raw data anyway.
Easy data and pipeline logistics and a single place to put stuff is, as we mentioned at the top, a critical evolutionary step in the evolution of your data warehouse anyway. Why not just stop there?
Because consider the risk a governed data model introduces into your ecosystem. Suddenly dashboards with executive visibility are dependent on the rickety output of this seemingly-failed data modeling process. And pipelines expect a place to drop incoming data too; if the data model changes, even the data you’ve got access to might be less valuable because of the data model. Your shaky data model has become critical-path to the business, and to manage these risks it all better go through some serious QA before anyone changes anything.
But that inability to change the data model automatically gives the current semantic layer a shelf-life. The current data model is only as good as the next data source.
If the data model can’t handle a new data source, you’ve got three courses of action:
- Bring back the data modeling team to hopefully get it right this time, finally.
- Don’t do anything new so you don’t change the reporting.
- Just add the new data anyway, into the same data warehouse, and get an intern or someone to figure out how to connect it someday.
Which choice do you make?
The root cause of this dilemma seems to be a kind of “square-circle”-type problem, where the requirements are just inconsistent. The requirement that the data model be able to absorb new kinds of data also ends up being the cause of the model’s instability. Preventing instability means the model can’t adapt to new data.
We want to discover new things about our business from our data model. As a result of that we will create new products or services with those discoveries. And those new offerings will create new kinds of data, which must also be incorporated reliably into the semantic layer. If we can’t even get it right the first time, after all the work, then maybe we just can’t do cool things.
The done-finished-done data model has to become obsolete to be any good.
The solution
Why is it inevitable your data model will become obsolete? Because traditional data modeling falls into a “local optimization trap,” a common enough problem in machine learning.
It is a fact that we will inevitably discover there’s discontinuities in our data – weird bits of business logic, unreliable sources, inconsistent descriptions of the same process, cosmic rays. These anomalies won’t fit into our model. They may or may not have been papered over in prior efforts. They often require a complete rethink of the domain we’re modeling. They are also among the quirks that make your business work, or not, and we need to model them anyway.
If data models must become obsolete to be any good, then we should plan for that change, manage and own it, and take advantage of the opportunities we get from planning ahead.
The first step in this ownership is realizing that data models – and your semantic layer – must be revised. The done-finished-done state doesn’t exist.
Once you’ve understood data models need to iterated to be useful, there are three easy steps you can take:
- Prepare for change
- Use a data catalog
- Scaffolding
Prepare for change
Change management is handled in mature software engineering and data science with tools designed to handle versioning, change management workflows, and automated error-free deployment. While the semantic layer is usually an afterthought in data science, data scientists frequently change their models and need to learn how to manage model change. In traditional data modeling change management is usually handled by not changing the model at all.
We’ve used the tools and processes of data science in our own iterative data modeling successfully:
- We treat our data models as code and put them into source control for use by other tools, and we require versioning and change management.
- We instrument our databases and pipelines so we know their states before, during and after changes to our models,
- We scan our sources whenever possible to construct data catalogs.
- We use CI/CD, DevOps, idempotent scripting, pipeline visibility tooling and as much automated data model testing as we can try out.
While much of this is easier in modern Cloud tools, some of this has been common practice – absent the actual change to actual data models – in better software shops for more than a decade. (Most software teams avoid data modeling entirely.) We appreciate that change is painful but also inevitable, and as a result, we use as many modern software tools as we can to help us manage changes to our semantic layers as we can adopt.
However bad your data may or may not turn out to actually be, being prepared for change is more than just thinking you might have bad data. You prepare to make the best of your situation.
In practice, that means accepting that your data will be weird, and there’s not enough of some kind and too much of the stuff you don’t need. Some critical-path sources will have awful data quality, and some will be impossible to get to. All of this is to be expected. First we’ll get it all co-located, and then we can identify and fill the gaps. But we have to deal with the data as it is and try to model it anyway.
Once you embrace the suck with your new tools, you’ll be able to face your data modeling challenges with some decent priors.
Use a data catalog
This might seem like a product recommendation, but it’s actually more of a process recommendation.
Most “data governance process” pre-Cloud was done in Excel or Sheets or worse. The modern data catalog automates much of that work, plus a lot else we used to do manually. Many catalogs also manage PII, and yours should too. Your catalog should also let you “turn on” specific regulatory PII requirements as they arise, such as new versions of e.g. GDPR or HIPAA. This is not a nice-to-have, and you will need this flexibility soon.
There’s some upfront work to get the data catalog to work, and catalog products cover a range of functionality. Some have APIs and some do not, and some (like Purview) don’t even call themselves a data catalog. But the use of a data catalog will make your modeling efforts much simpler.
First, because a data catalog can track data model changes and various associated table and field metrics through your entire ecosystem. Changes to upstream systems should be easy to spot, so you can integrate them before they disrupt your VPs plans. Catalogs will also often help with naming conventions, lineage analysis, and report and dashboard inventories. They create what is effectively a card catalog for your data warehouse.
Second because before data catalogs became a product, PII management made data modeling much harder. Customer data models can be very simple, but because most fields in a customer data model are different kinds of PII the model is often broken up, across multiple domains or layers, with annexes or “ears” tacked on to handle exceptions. A data catalog can handle PII outside of the model itself, and helps keep the customer simple.
Scaffolding
It’s easier to solve a problem by starting with a hypothesis about the solution, or a first draft, or a “spec.” Even when the only feedback provided on the spec is from the writer, the act of laying out the plan or argument produces a better result. So, scaffolding should be used with data models.
We use patterns of hypotheses in all of our work. They help us move quickly.
Our data modeling practice begins with the hypothesis that all of a client’s data can be inserted into generic models, that the big problem with data modeling is just mapping various sources into the same set of ORDER_NO or PURCHASE_ORDER_QTY for CAMPAIGN_NAME fields, over and over. We find the nearly-forgotten data model pattern books of Len Silverston and David Hay to be excellent sources of scaffolding patterns, as well as David Giles’s advice on agile methods in data modeling.
Now we know that the working hypothesis is wrong, just obviously. Hilariously naive. But it gives us a starting point, one we can use to make progress. These frameworks give us a theoretically objective way to trap the weird bits of business logic that make your company successful. And since we can automate much of our formerly manual model tracking work with the data catalog and automate change with our change-management tools, we can begin to figure out how to deal with the failure of our ridiculous hypothesis.
Scaffolding should evolve into something that works for you, and it can be re-used when you need to kickstart your evolution again. How you choose to create a scaffolding for your data – and again we have a few opinions about how that works – is up to you. The books mentioned above are good starting points.
But the point of scaffolding is to provide a hypothetical data model that can be used to start data modeling, surface failures quickly, and get better.
Conclusion
Good database modeling is the foundation of a good semantic layer but it’s hard to do, risky and quite possibly logically impossible anyway. The practices are archaic and it’s not clear, again, if better practices would necessarily help.
We think it is possible to build a reliable and flexible semantic layer. You need to be willing to embrace hypothesis-driven architecture along the lines of our scaffolding approach, and you need to use modern dataops and software engineering best practices. You should also use some kind of data catalog product to make the operational components of your modeling practice more efficient.
But if you start by acknowledging you’re going to run into problems, prepare for them ahead of time, and acknowledge the process doesn’t stop, you’ll make serious progress on your semantic layer.