


Data Warehouse development usually proceeds down one of two paths. These paths function as “process architectures” because they structure projects’ planning and execution.
After we show why the first two paths don’t work all that well, we’re going to suggest a third path. This third path is also a process architecture, but it is informed by the data architecture that successful data warehouses end up using anyway. The “Office Space” model is a more reliable process architecture and produces more valuable data architectures.
The data warehouse
There are five data management layers common to successful data warehouses.
Notice we said “successful” data warehouses: Data warehouse projects fail for lots of reasons, but the most common is because the warehouse itself is dysfunctional. Every successful data warehouse needs five layers to work properly:
- A staging area containing collocated copies of source records, including copies of files. This is also called a “Data Lake.”
- A business operations layer that arranges and consolidates source data into orders, customers, products, marketing campaigns and whatever other age-old business concepts the business uses to navigate. This is also called an “Operational Data Store” or ODS.
- An analytical layer that denormalizes tables in the operational layer by their formal relationships, making it easier for analysts to discover, pivot and report on those relationships.
- A reporting layer where people can create visualizations of data.
- ETL tool(s) that automate the movement of records from one layer to the next in a repeatable, reliable and auditable fashion.
Why would a data warehouse missing one of these layers be dysfunctional? A detailed explanation will need another forum, but we can understand why with an easy architectural analogy. Look around your current office space and try to imagine which components could be sacrificed short- and long-term before the space becomes unusable.
Carpets, art, and fancy espresso machines are superfluous. Hallways, conference rooms, restrooms, and electricity are not.
Some space users may think conference rooms, for example, are unnecessary because they never interact with their coworkers except via messaging apps. Soon enough we discover discussions between more than two people distract the entire office, we realize we need a place to go for phone calls and brainstorming, and even the solitary individual contributor sees the need for conference rooms they’ll never personally use. Eventually, in an office with no conference space, the occupants make their conference rooms, maybe by appropriating the local coffee shop or working from home. It turns out conference rooms are critical to the success of an office space: It’s just not a real office without conference rooms.
The five data warehouse layers we listed above are similar. A data warehouse project missing one of those layers will not function as it needs to, either organically growing the missing layer or failing to serve its users.
This may seem like a “well duh” philosophical point people argue about in their college dorms. But this turns out to be much more than a definitional point: An office space without conference rooms will force-convert some of its space to satisfy the missing function, or its users will consider it a failed office space. Similarly, a data warehouse system missing one or more critical layers will try to find a way to perform the missing function. Still, it will likely be considered a failure by its intended users.
The first two paths we’ll discuss below try to build a data warehouse without all of the layers. It’s typical to assume data warehouses take a lot of time to produce value, and even then, they often fail to catch on with their intended users. Project leads hoping to avoid a failed project will try to cut components or expectations to get to value quickly. And like a new office space without conference rooms, users will be stuck with a half-baked facility that doesn’t do what they need.
The home renovation model
The first path we’ll talk about is the ”Home Renovation” model. We call it that because it works like a room-by-room home renovation project: One layer at a time, with the goal of minimizing disruption to any functioning components or business processes.
Development teams with lots of experience may be able to build more than one layer at a time, but usually teams build one layer until it’s completed. The theory behind this approach is that once the basic technology choices have been made and each layer is carefully built, at the end of the process the organization should have a well-designed, solidly-built, tightly-integrated system.
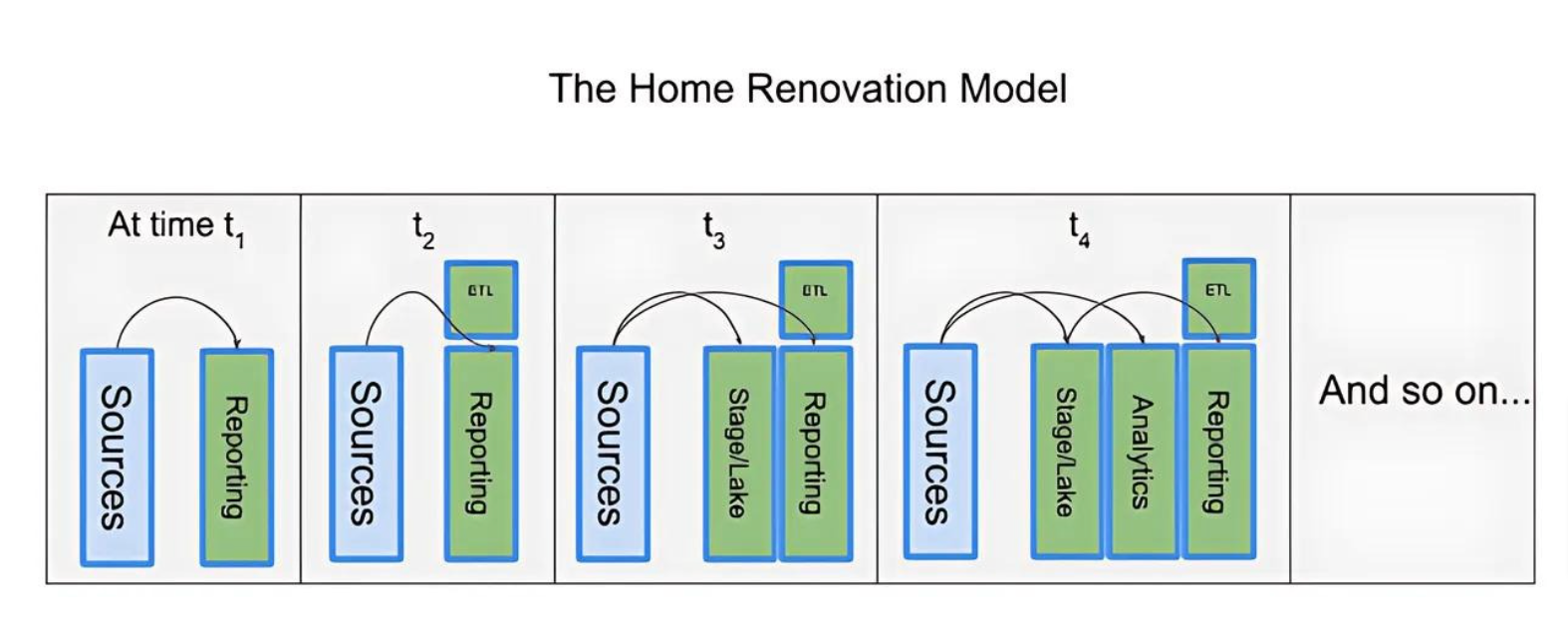
Teams with strong architects usually prefer the “Home Renovation” model. The goal is to do things right the first time, and that means disciplined development of each layer. It’s not unusual for this approach to take multiple years to complete. Project leads often need to justify labor and tooling costs for each new layer, mostly because it’s easier to swing timelines for portions of the solution than it is to justify the whole actual timeline, which may be quite long.
But since you need each layer for the whole thing to work right, project leads also have to find value for business sponsors who may be on the outside looking in for much longer than they’re comfortable.
Sponsors may wonder how much architecture has to happen – and be implemented – before what they need is built. While project leads may try to explain this process with an analogy to home renovation, anyone who’s watched TV knows it takes forever and there’s often multiple independent contractors involved. Individual layers may be useful to very specific sets of users, but unless the business sponsor is one of those users they’ll need to be pretty altruistic.
Like an office that has electricity and hallways but no conference rooms, a data warehouse built on the “Home Renovation” model is always partly finished and partly broken, with piles of wire left lying around in the corners just in case.
The “made-to-order” model
The second path, or the “Made-to-Order” model, assumes the fastest and most efficient way to support a given set of report requirements is to build a system for just those reports.
Scoping “Made-to-Order” systems is comparatively easy: The development team reverse-engineers target reports, arranging and collocating just enough source data so the reports more-or-less “fall out” of the resulting system.
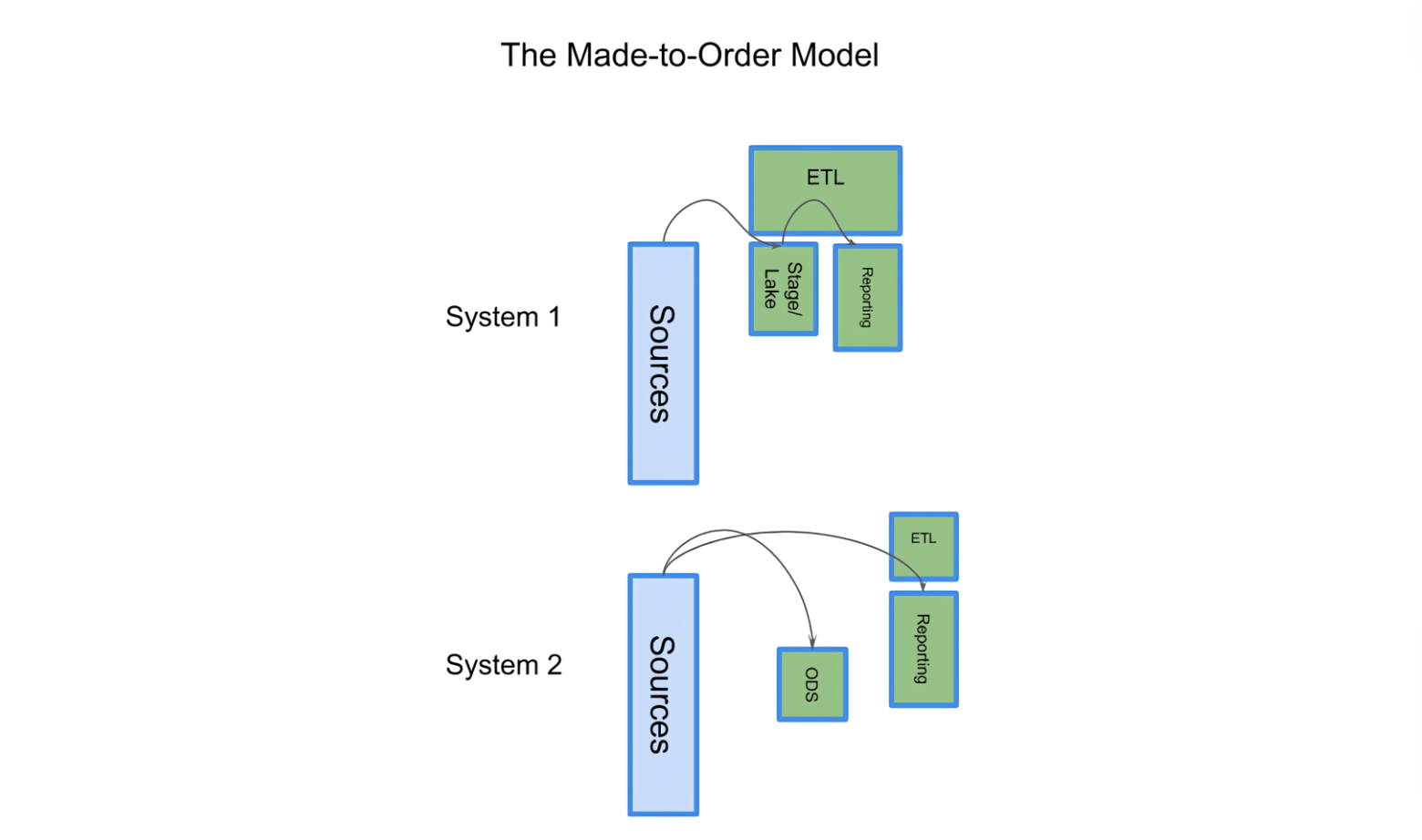
While everyone involved in “Made-to-Order” projects hopes that new reports or requirements can share a data architecture with old reports, there’s usually very little reuse of infrastructure or architecture across time. Any given set of reverse-engineered reports might be implemented with the full complement of Data Warehouse layers. But usually, they aren’t, and if it’s possible to shortcut the production of target reports by avoiding layers entirely, many teams on the second path will choose the shortcut. This can make the “Made-to-Order” model attractive to smaller teams, teams with less experience building reporting systems, or with business sponsors or teams where the project management function exerts a lot of authority.
Building a “Made-to-Order” data warehouse with very little infrastructure and nothing that might look “extra” to the deliverables is possible. This makes a tidy project from a budget standpoint. But the result is a system that intentionally overfits its intended outputs, leaving no room for the unexpected. This is great when report requirements never change and less so for business processes that do.
Risks of the first two paths
Both paths take lots of organizational overhead to prioritize, schedule, build, test, implement and ultimately support the warehouse.
All of the pieces still need to be justified sequentially, and so each of the various layers and/or systems have to be packaged more-or-less piecemeal and sold to sponsors anew as they’re built. Teams that have worked in either model before can often create bigger packages of product, but there’s still the need to “project manage” each piece of work separately while it’s happening. And because in both models teams work in relative isolation it’s rare that all the pieces work together well enough to make outcomes predictable.
The extended timelines of the “Home Renovation” model introduce two risks. First, multi-year data warehouse projects need lots of organizational discipline. It’s best if the architect at the end of the project is the same as the one who started it, and the people doing the work should stay the same too. It’s rare to find architects who agree strategically about multi-year projects, and it’s equally rare that a data warehouse team is able to keep staff – including architects – over an extended timeline.
One risk of the first path, then, is that the longer the project the more architects get a say. If the Data Warehouse were an office with multiple architects, we’d end up with lots of different looking rooms, only some of which you could get to from where you’re at now.
The second risk is that business needs and priorities will change over the course of the project. So will the technologies available to execute the plan, because the odds are good some of the original choices will just not work for their intended use-case. For example, a staging layer carefully assembled over the course of a year for Finance is probably useless when it’s suddenly expected to manage weblog data for Marketing. Very similar: New VPs decide they want new BI tools. The “Home Renovation” model runs into trouble then because the tightly-coupled process architecture has an opportunity cost. The second risk of the “Home Renovation” model is that the longer the project the more business sponsors it has to satisfy to stay viable.
The “Made-to-Order” model avoids the second risk by ignoring architectural consistency as a first-class concern. Instead the plan is to support a specific set of needs in a specific timeframe. The resulting system will almost certainly be irreconcilable with the organization’s other systems. The second path creates multiple versions of each layer for each target set of reports and in some cases no layers as such, at all. The demotion of architectural consistency means semantic consistency between systems is accidental, if it’s even possible. The organization ends up with sets of reports that can’t talk to each other: One report suite uses SKUs and another PRODUCT_NO, for example, or one counts customers and the other counts distinct customers. The only way to figure out the difference is to open up the respective code bases and build a functional semantic layer that can merge the systems. The risk then is that the more efficient the system the less useful it is to the organization as a whole.
A second risk of the “Made-to-Order” model is technological: Different technologies will inevitably be used to implement different suites. In practical terms this means not only that one solution uses MySQL and another MongoDB, that one report suite is in Tableau and the next is in Cognos, but that one solution organizes data in a star schema and the other turns XML files directly into Excel workbooks via shell scripts. Before the business can connect the dots shared by these two solutions much of the semantic and technological value created by the projects needs to be stripped out. Analysts must export both datasets to Excel, add their own bridging functions, and more-or-less do the semantic work missing in the original projects. The missing data warehouse functions will still need to be performed, but in implicit, uncoordinated, task-specific ways. The risk is that each solution is unique.
It’s certainly possible to address the risks of both paths.
Stringent governance, documentation and hiring requirements could be enforced in the case of teams pursuing the “Home Renovation” model, for example. Teams going down the second path might be required to use an existing Finance data warehouse as a source system or architectural model, to ensure at least consistency in bottom-line numbers.
But these risks are baked into each approach, and mitigation is only as effective as the diligence of the extended project team. A project manager who’s a stickler for stakeholder review, for example, can ensure projects on the first path attract new business owners or architects and take so long that they inevitably fail. Developers who really don’t like data modeling ensure teams working the second path produce a zoo of irreconcilable systems, and chaos when the business tries to understand itself cross-functionally.
The “Office Space” model
There is a third path, though. We’ll call it the “Office Space” Model.
The “Office Space” model starts from the premise that Data Warehousing is a mature software development practice that can use stable and productive patterns to develop solutions. The primary problem with data warehousing is not design or architecture, its logistical: Successful data warehouse development uses established design patterns to coordinate development across layers, and to guide the selection and configuration of the technologies needed to support the system.
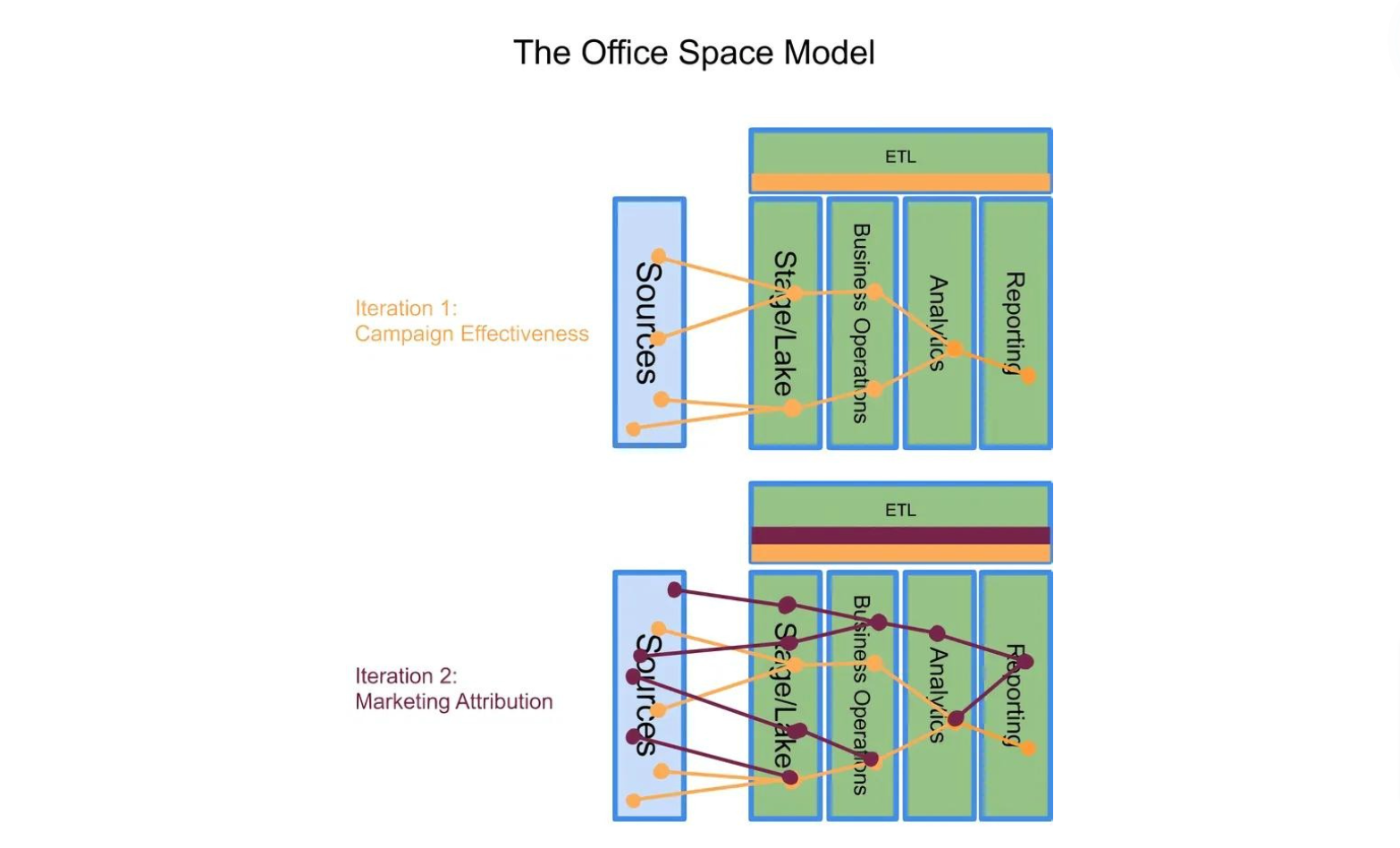
A Campaign Effectiveness report suite needs the same semantic elements whether the relevant ecosystem is {SAP, Salesforce Marketing Cloud, Redshift, Airflow} or {Adobe Marketing Cloud, Axapta, Oracle, hand-made Python scripts}. Supporting a Marketing Attribution report suite alongside the Campaign Effectiveness suite is partly a matter of adding new brand names to the relevant ecosystem. But there is a specific set of attributes needed to support an Attribution suite, and many attributes are shared with the Campaign Effectiveness suite.
What matters for either suite is
(a) the necessary attributes are available in the sources and
(b) the step-by-step transformation and consolidation of attributes into reports be repeatable, auditable and functional for multiple audiences.
In other words, a Campaign Effectiveness report measures the same things whether the source is Adobe or Salesforce, whether the data is stored in Oracle or Redshift, and whether the reporting tool is Cognos or Tableau.
“Office Space” model proponents make a couple of assumptions. The first architectural assumption is that every good Data Warehouse will need the five layers we mentioned at the top.
Not all of the infrastructure implied by these layers needs to be mature before its useful, and a purely-functional-but-not-pretty layer is easy to build. There is very little difference between an expensive “Data Lake” and a traditional staging area, for example. The main point of the staging area in the typical Data Warehouse architecture is to replicate source-system data structures and prepare data for loading into a clean production area; the main point of a “Data Lake” is to allow users to query multiple collocated sources in their original structures. As long as both of those requirements are met – keep untransformed copies of the original data in the same db – the staging layer functions as both a data preparation area for a production environment and a data lake.
Similarly the Reporting layer might start out as Excel, perhaps as an existing set of workbooks used by a Finance or Supply Chain team, and as time allows grow to include a more formal BI tool such as Qlikview that simplifies report management. Often an organization already has all the infrastructure it needs to support the functions performed by a given layer; what’s missing is explicit coordination of those implicit functions with other functions. In practical terms, discovery, coordination and planning can turn a collection of seemingly disconnected operations into a full-fledged layer. Coordination across layers is part of what makes the warehouse work.
The second architectural assumption in the “Office Space” model is that the actual implementation of any of these five layers is best done by modifying generic patterns to accommodate specific cases. That is, any given layer has a stable set of design patterns that guide implementation, most of which have converged on a relatively small code base. UPSERTs, for example, can be done a couple of different ways. There’s no practical need for an organization to try something different when those techniques just work, whether implemented in an Informatica UPSERT component or an ANSI SQL MERGE statement. Someone may someday come up with a more efficient technique, but it’s best to run those experiments once the system is working and not before. Any given layer should be based on its most appropriate patterns and customized as needed for the local environment.
For example many organizations studiously avoid creating a “business operations” layer, thinking the construction of an ODS requires months to figure out what a “sales order” or “customer” data model would look like. But data model pattern repositories such as the volumes written by Len Silverston or David Hay cover 80+% of what an ODS should include. The Hay/Silverston patterns will readily map to local circumstances, and since those patterns have become de-facto standards in ERP or CRM systems it’s also more than likely source systems can be mapped into the patterns too.
In practice the second assumption implies that any staging area/Data Lake built for a modern enterprise will eventually need to store orders, customers, campaigns, products, weblogs and email data, and so on. A Finance-oriented sponsor may not think weblog data is immediately important. But the opportunity cost of not planning for large volumes of data is easily enough explained, especially to Finance people, and a storage mechanism that can accommodate that data should be written into the plan. The project plan should already have boxes on architectural diagrams and data models for obvious domains, and constructing the lake/staging area means assigning sources, resources and priorities to those boxes. Experience tells us who in the business is likely responsible for source systems and how those systems must be related, at least at a high level, and so the discovery process is also straightforward. At some point the business will want to see campaign and campaign-related communications pivoted with orders; since that’s just a given, the inevitable-if-eventual need should simply be factored into the construction plan and used to solicit requirements. But as there are only so many ways to measure campaign effectiveness, and there are industry best practices that make the implementation options for campaign effectiveness reporting obvious, the necessary requirements are straightforward and stable to a certain degree of approximation across all of the various platforms. Implementation details will vary a lot, but the whys and hows will not.
Since one of the report suites a warehouse must eventually support is “Campaign Effectiveness” or “First-Purchase Cohort,” either of those suites can be used to dictate construction of all of the layers. In the “Office Space” model each layer’s construction is informed by a set of patterns, and each set of patterns are configured based on the seed requirement.
Because “Campaign Effectiveness” is the report the client is paying to see, the components necessary to support it can be dropped into place in each layer. The same sets of fields and records need to be extracted from the various campaign-management systems into the Lake; standard customer, order and campaign data models can be created in the operational layer; pivots in the analytical layer can be built by joining the relevant ODS tables; and a set of campaign-effectiveness reports can be built showing trends over time. People who’ve worked in data warehousing long enough have done one or more of these operations more than once, and there is very little point in wasting time wondering what ought to be done in each case. Established and reliable patterns exist for each of these domains, some of them literally thousands of years old. Why would we reinvent the wheel? The serious design question is how much of this can be done in parallel.
Further, because the intent of the data warehouse is to support a wide set of use-cases the acquisition of data to support a specific use-case isn’t restricted to a subset of source data. If we can get all of the order data then we should get it with a SELECT *, even if our current use-case is restricted to ecommerce orders. If we know there’s four campaign-management systems then we work to incorporate all of them into the Lake, even if only one of those systems contains the email data we need to support the particular report currently motivating our work. We can do this because the only effective difference between those various campaign-management systems, from an ETL standpoint, is the SQL query executed against the storage mechanism. Campaign-management systems may be better or worse from the standpoint of their local users, but their semantics is necessarily the same, and the data needed to support a campaign effectiveness report is semantically the same from one system to the next.
To reiterate, the “Office Space” Model presumes the construction of each layer can more-or-less happen in parallel.
Constructing interfaces between the layers is a mapping operation coordinated by specialists, who are guided by the relevant pattern and the report suite paying for the operation. Unlike the first two paths, where Project Management assumes there are lots of unknowns, each of the components required to build a data warehouse is pretty straightforward to build, has some established guidelines for scoping timelines, and can be prioritized based on its near-term utility to the business sponsor. Actual implementation may require the coordination or prioritization of specific tasks, as in when we need to figure out which order management system has the campaign codes in it, but there’s no real substantial question about what needs to happen once we figure that out. These architectural requirements aren’t debatable, any more than it’s debatable that a successful office space needs conference rooms.
As in the second path above, iterative development in the “Office Space” model is motivated by a specific set of reports: The “Campaign Effectiveness” suite the sponsoring VP is desperate to see, for example. Particular instances of various patterns will introduce complexity into the mappings between one layer and the next – one campaign-management system uses a hierarchical storage system and another is relational, for example – and each system may be painful to map to the generic semantic model dictated by the final reports. But because specialists at each layer are there to perform the mapping and coordinate across layers, and “we already know the answer” or the goal-state of the mapping, we don’t need as much work to complete the mappings as we would if we were building a “Made-to-Order” system.
So the “Office Space” model achieves the quick results of the “Made to Order” model while avoiding the spiral of local optimization that makes the second path a dead-end. Because we’re constructing our layers in parallel, and because we’re starting from well-worn patterns of data modeling and data movement, it’s also much easier to maintain continuity and consistency between the layers. That’s how we avoid the drift in architecture, conventions and semantics that haunts the first path.
Finally, because we’re implementing patterns instead of locally optimizing for the short-term we have an easier time migrating the system from one technology platform to the next. Our job is ultimately to produce a series of mapping functions that can connect source fields to target fields. Those mapping functions will have particular implementations for particular platforms, but our starting point is the mapping function and not the implementation.
Technologies change, but it’s the mapping functions that are really important: We know that field A from source X is equivalent to field B in report Y via mapping function M between the Stage and ODS layers. Its that mapping we move from one warehouse implementation to the next.
Conclusion
The net result of the “Office Space” model is a fast, flexible and readily-useable data warehouse system. It maintains a higher degree of architectural consistency than systems built by either of the other two approaches and offers a time-to-completion that compares favorably with the second path. The “Office Space” model dramatically lessens the risk of building a data warehouse, ensuring maximum functionality, quantifiable business ROI and reusable infrastructure.


