


Filternavigation und Pagination sind Standardfunktionen von Online-Shops. Aus Sicht der Suchmaschinenoptimierung ist der Umgang mit ihnen knifflig. Einerseits sollen Kategorieseiten in Suchmaschinen eine möglichst hohe Sichtbarkeit erreichen, andererseits ist Duplicate Content zu vermeiden. Best Practices sind gefragt!
Kategorieseiten von Online-Shops bieten grosses Sichtbarkeitspotential in Suchmaschinen: Viele Kategoriebezeichnungen weisen hohes Suchvolumen auf, so auch ihre Kombinationen mit Filterbezeichnungen. Die Steuerung der Indexierung ist daher aus Sicht der Suchmaschinenoptimierung essenziell – aber nicht das einfachste Thema. Es gilt für möglichst viele Keywords eine möglichst gute Sichtbarkeit mit möglichst sinnvollen Zielseiten zu erzielen. Gleichzeitig dürfen die Funktionen Filtern, Sortieren und Blättern keinen Duplicate Content erzeugen. Relativ selten ist das bei Online-Shops alles sauber umgesetzt.
Die Herausforderungen, Probleme und Best Practices dieser drei Funktionen werden beispielhaft anhand der Kategorieseite “Herrenbekleidung – Hemden” von zalando.ch besprochen: www.zalando.ch/herrenbekleidung-hemden/
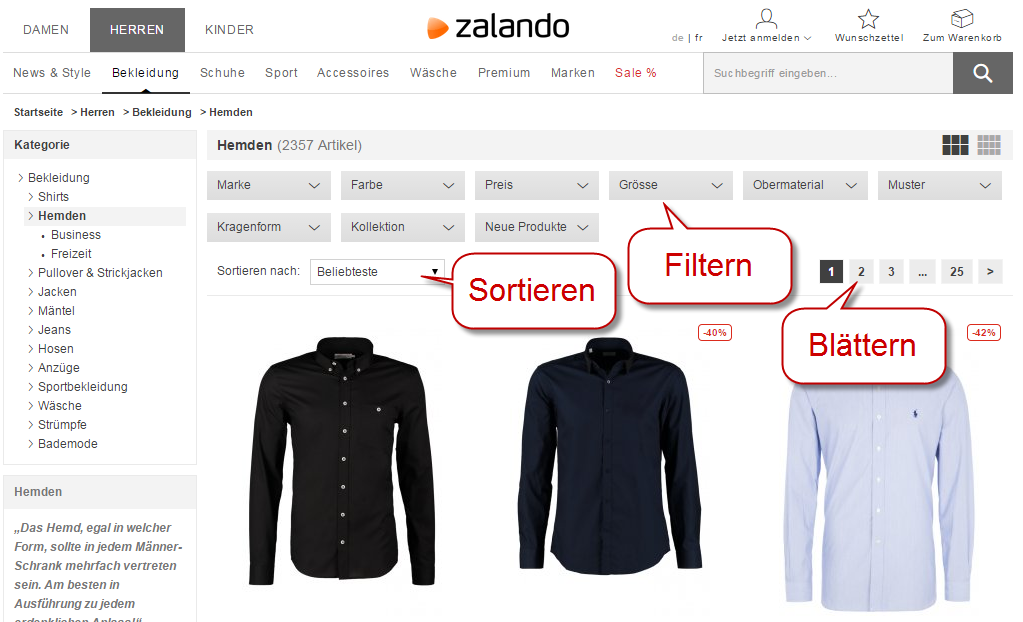
1. Filtern
Filternavigation: Mittels weniger Klicks auf Filter können die Shop-Besucher:innen das Sortiment einer Kategorieseite auf ihre Bedürfnisse einschränken.
Wenn hier von Filternavigationen und Filtern die Rede ist, sind gleichzeitig auch Facettennavigationen (resp. Facettensuchen) und Facetten gemeint. Obwohl oft synonym verwendet, bestehen durchaus Unterschiede.
Auf der Kategorieseite “Hemden” von zalando.ch können Hemden nach diversen Kriterien gefiltert werden, u.a. nach Farbe und Preis:
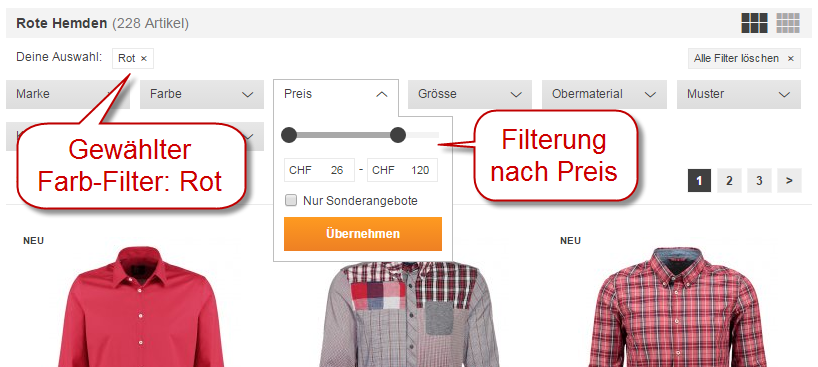
Für jede neue gefilterte Ansicht der Kategorieseite entsteht jeweils auch eine neue URL, z.B. für die Filter “Rot”, “CHF 26.- bis 120.-” und deren Kombination:
www.zalando.ch/herrenbekleidung-hemden/_rot/ www.zalando.ch/herrenbekleidung-hemden/?price_from=26&price_to=120 www.zalando.ch/herrenbekleidung-hemden/_rot/?price_from=26&price_to=120
Problematik Filternavigation
Bei den meisten Filternavigationen entsteht bei jedem Klick auf einen Filter eine zusätzlich “Filter-URL”. So existieren durch die zahlreichen möglichen Filterkombinationen und Mehrfachauswahlen unzählige URLs – und zwar für den praktisch identischen Inhalt (einzig die aufgeführten Produkte sind unterschiedlich). Die Frage ist, wie man mit diesen unzähligen Filter-URLs einer Kategorieseite umgehen soll. Die Herausforderung sei anhand zweier Extrem-Szenarien und einer Best Practice erläutert:
Filter-Szenario 1: Keine Steuerung der Filter-URLs
Die Indexierung der Filter-URLs wird nicht gesteuert und den Suchmaschinen überlassen. Wie oben geschildert kann es tausende URL-Varianten einer Kategorieseite geben. Dadurch entsteht Duplicate Content: Identischer oder nur minimal unterschiedlicher Inhalt ist über diverse URLs aufrufbar. Duplicate Content führt zwar nur in Fällen von Absicht oder grober Fahrlässigkeit zu einer direkten Abstrafung bei Google. Aber die Problemfelder sind aus SEO Sicht dennoch dramatisch: Das Crawling-Budget von Google wird verschwendet, wodurch womöglich neuere Seiten verzögert oder gar nicht entdeckt und bei Google indexiert werden. Zudem wird die Power von Backlinks und weiterer ranking-relevanter Faktoren nicht auf wenige, definierte, sogenannte kanonische URLs gebündelt, sondern auf zahlreiche URLs verteilt, von denen dann oft keine URL wirklich gute Positionen in Suchmaschinen erzielen kann.
Filter-Szenario 2: Keine Indexierung der Filter-URLs
Um Duplicate Content vorzubeugen oder aus anderen Gründen, gehen zahlreiche Online-Shops ins andere Extrem: Als einzige URL wird die ungefilterte Kategorieseite zur Indexierung bei Google freigegeben. Im genannten Beispiel wäre das www.zalando.ch/herrenbekleidung-hemden/. Sämtliche Filter-URLs werden mit einer der unten aufgeführten Möglichkeiten von der Indexierung bei Google ausgeschlossen. So vorgehend hat der Online-Shop ein herrlich schlankes URL-Set in den Suchresultaten von Google. Aber auch ein massives Problem: Es wird enormes Ranking-Potential verschenkt. Denn diese eine URL kann niemals alle Keywords abdecken, welche rund um das Thema “Hemden” interessantes Suchvolumen aufweisen. Ihr Kategorietext wird wohl die Begrifflichkeit “Hemd” und ein paar Kombinationen wie “Hemd kaufen”, “Hemden Shop” etc. beinhalten, aber für Suchanfragen wie etwa “rotes Hemd” oder “Olymp Hemd” wird sie kaum relevanten Inhalte bieten können. Das ist gravierend, denn die zwei genannten Suchanfragen werden doch recht häufig gegoogelt und würden mit entsprechenden Rankings einiges an Traffic und Umsatz generieren können.
Eine weitere Problematik kommt hinzu: Sollte die Kategorieseite www.zalando.ch/herrenbekleidun… wider Erwarten für Suchanfragen wie “rotes Hemd” oder “Olymp Hemden” gute Positionen in Google einnehmen, würden Suchende auf dieser Seite nicht genau ihre gewünschten Ergebnisse vorfinden und müssten erst die blauen und grauen Hemden resp. solche von Adidas und Esprit etc. wegfiltern. Benutzerfreundlicher wäre es, wenn als Suchergebnis gleich eine passend gefilterte URL wie www.zalando.ch/herrenbekleidun…_rot/ aufgeführt würde.
Best Practice: Gezielte Indexierung relevanter Filter-URLs
Zwischen den beiden oben geschilderten suboptimalen Extremen liegt der anzustrebende Mittelweg: Filter-URLs, deren Inhalte Suchvolumen aufweisen und zusätzlich dem Suchenden als Suchresultat einen Nutzen bringen, sollen durch Google gecrawlt und indexiert werden und schliesslich gute Suchresultate erzielen. Der grosse Rest der Filter-URLs soll nicht in den Index von Suchmaschinen gelangen und womöglich erst gar nicht gecrawlt werden.
Diese Best Practice wird im Folgenden diskutiert und ist hier vorgängig in Kurzform schematisch abgebildet:
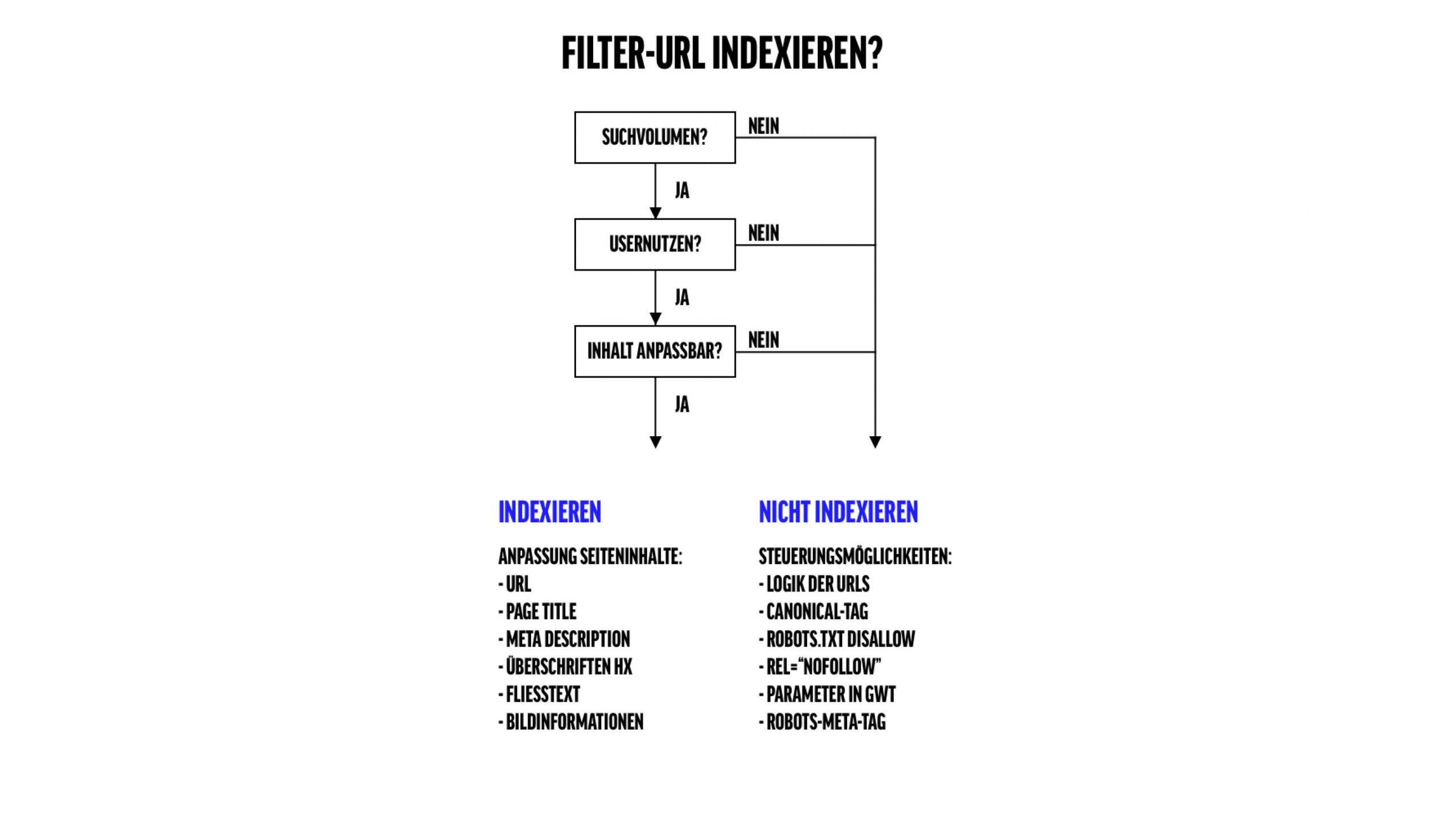
Indexierung von Filter-URLs: Ja oder nein?
Ob eine Filter-URL von Suchmaschinen indexiert werden soll, kann von folgenden Faktoren abhängen:
- Suchvolumen: Weisen die Keyword-Kombinationen [Kategorie] x [Filter] Suchvolumen auf im Google Keyword Planner? Für das aufgeführte Beispiel weisen Kombinationen mit Farben wie “rotes Hemd” oder “blaues Hemd” etwas und Kombinationen mit Marken wie “Olymp Hemden” wesentliches Suchvolumen auf. Kombinationen etwa mit Preisen hingegen können getrost von der Indexierung ausgeschlossen werden.
- Usernutzen: Hat die gefilterte URL-Variante einen potenziellen Nutzen, wenn ein User via Suchmaschine darauf stösst? Z.B. die meisten URLs mit mehreren gesetzten Filtern in der Regel nicht, da sie zu spezifisch sind um in dieser Kombination als Suchresultat öfters nützlich zu sein.
- Inhaltliche Anpassungsmöglichkeiten: Können nebst der URL weitere Seiteninhalte auf die gewählten Filter abgestimmt werden? Dies ist für eine Filter-URL relevant, um nicht als Duplicate Content eingestuft zu werden und um in Google gute Positionen erzielen zu können. Details im Absatz “Filter-URLs: indexieren”.
- Googles Laune: Die Algorithmen von Google werden laufend angepasst. Was heute als Duplicate Content bewertet wird und was indexiert wird, wird es morgen ggf. schon nicht mehr. Sich auf dem Laufenden halten und beobachten lautet die Devise.
Filter-URLs: Nicht indexieren
Um Filter-URLs nicht von Suchmaschinen indexieren zu lassen, gibt es folgende Steuerungsmöglichkeiten:
- Logik der URLs: Die Reihenfolge der Filter in der URL muss immer gleich sein, egal in welcher Reihenfolge die Filter gewählt werden (Also nicht einmal www.zalando.ch/herrenbekleidun… und einmal www.zalando.ch/herrenbekleidung-hemden/rot_olymp-luxor/. (Das gilt natürlich auch für URLs, die für die Darstellung der Filter Ordnerstrukturen oder Parameter verwenden, z.B. www.domain.ch/hemden/olymp-lux… oder www.domain.ch/hemden/?marke=olymp-luxor&farbe=rot). Diese Massnahme verhindert unnötige URL-Varianten.
- Canonical-Tag: Das Canonical-Tag ist auch heute das erste Mittel, um nicht zu indexierende Filter-URLs zu steuern. Es ist ein Meta-Tag, also eine Code-Zeile, welche auf der nicht zu indexierenden Seite im Head-Bereich eingebunden wird, und auf die sog. kanonische Version der URL verweist. Ziel: Die URL wird nicht von Google indexiert und allfällige Power von externer oder interner Verlinkung sowie weiterer ranking-relevanter Kriterien wird auf die kanonische URL gebündelt. Beispiel: Die Filter-URL www.zalando.ch/herrenbekleidun… (Farb-Filter=Rot) soll indexiert werden. Wird diese URL aber weiter gefiltert, sollen die dabei weiter entstehenden Filter-URLs nicht indexiert werden. Würde beispielsweise weiter nach Preis gefiltert, würde das Canonical-Tag auf der Filter-URL www.zalando.ch/herrenbekleidun…?price_from=26&price_to=120 demnach folgendermassen definiert:
<link href=”http://www.zalando.ch/herrenbekleidung-hemden/_rot/” rel=”canonical”
- Robots.txt disallow: Im Februar 2014 veröffentlichte Google Best Practices für den Umgang mit Facettennavigationen. Darin wird die Möglichkeit aufgeführt, zusätzlich zum Einsatz des Canonical-Tags alle nicht zu indexierenden URLs mit einem eigens dafür vorgesehenen, zusätzlichen Ordner auszustatten und diesen sodann per robots.txt vom Crawlen und Indexieren auszuschliessen. Dieser Vorschlag überraschte etwas, weil die Aussage von Google bislang war, man solle alles crawlen lassen und dann mit dem Canonical-Tag die Indexierung steuern. Der Vorteil dieser Methode ist, dass a) das Crawling durch Google eingeschränkt wird und damit b) auch die eigene Server-Belastung reduziert werden kann. Diese Methode wird noch selten angewandt. Der Code in der robots.txt könnte für Filter-URLs mit der Struktur www.zalando.ch/herrenbekleidun… folgendermassen aussehen (der zusätzliche, nicht zu crawlende Ordner heisst hier beispielhaft “filter”):
User-agent: * Disallow: /filter/
- rel=”nofollow”: Alternativ zum Einsatz von robots.txt, aber ebenfalls zusätzlich zum Canonical-Tag, beinhalten die oben erwähnten Best Practices den Einsatz von rel=”nofollow” in den Links von Filtern, welche nicht zu indexierende Filter-URLs generieren. Dieses Attribut, welches in das <a>-Tag eingebunden wird, dürfte das Crawlen der ganz grossen Anzahl nicht zu indexierender Filter-URLs reduzieren, aber nicht so weit stoppen wie z.B. die Variante mit den robots.txt. Ein entsprechender Link wäre folgendermassen aufgebaut:
<a href=”http://www.zalando.ch/herrenbekleidung-hemden/_rot/?price_from=26&price_to=120″ rel=”nofollow”>
- Weitere Möglichkeiten: Zur Vermeidung von Duplicate Content oft auch zum Einsatz kommen die Steuerung von Parametern in den Google Webmaster-Tools oder das Robots-Meta-Tag (“noindex”).
Filter-URLs: Indexieren
Damit die gewünschten Filter-URLs einer Kategorie tatsächlich indexiert werden, dürfen sie natürlich nicht mit einer der oben aufgeführten Methoden vom Crawlen oder Indexieren durch die Suchmaschinen ausgeschlossen werden. Insbesondere das Canonical-Tag und die robots.txt könnenfalsch angewendet grossen Schaden anrichten!
Damit Google die kanonischen URLs nicht als Duplicate Content der eigentlichen Kategorieseite oder einer anderen gefilterten Variante beurteilt, muss der Seiteninhalt so weit als möglich mit dem gewählten Filter-Kriterium ergänzt werden. Dies macht zudem ein gutes Ranking dieser Seite für die gewünschten Keyword-Kombinationen erst möglich. Angepasst werden auf z.B. “rotes Hemd” sollten nach Möglichkeit:
- URL
- Page Title
- Meta Description
- Hauptüberschrift hx
- Fliesstext
- Bildinformationen (Dateiname, Alt-Attribut, Bildlegende)
Abfrage des Status Quo
Mit u.a. folgenden Methoden lassen sich die aktuelle Steuerung der Indexierung einer Filternavigation sowie der Stand im Google-Index eruieren:
- Quellcode: Im Seitenquelltext nachvollziehen, ob Canonical-Tag, rel=”nofollow” oder Robots-Meta-Tag (“noindex”) eingesetzt werden. In der robots.txt kontrollieren, ob relevante Ordner oder Parameter ausgeschlossen werden.
- Site-Suchabfrage: Mittels Site-Suchabfrage bei Google prüfen, welche/wie viele URLs für eine bestimmte Kategorie indexiert sind. Abfrage für das genannte Beispiel u.a. “site:www.zalando.ch/herrenbekleidung-hemden/”.
- Suchabfrage mit Keyword-Kombination: Prüfen, welche URL der Domain Google bei der Suche nach einer Filter-Auswahl wie “Hemden rot” oder “Olymp Hemden” ausgibt. Übereinstimmung mit der Steuerung?
- Tools: In Tools wie Searchmetrics oder ScreamingFrog nach Duplicate Content oder dem Einsatz von Canonical-Tags Ausschau halten.
Wie macht’s zalando.ch?
Im Quelltext ist ersichtlich, dass die Steuerung der Indexierung mittels Canonical-Tag stattfindet. Offenbar hat sich zalando.ch dazu entschieden, die Filter-URLs der Filter Marke, Farbe und Grösse indexieren zu lassen – auch in Fällen von Mehrfachauswahlen, wie z.B. www.zalando.ch/herrenbekleidung-hemden/olymp-luxor_rot_groesse-40/. Alle weiteren Filter werden mittels Canonical-Tag von der Indexierung ausgeschlossen.
Inhaltlich auf die Filter-Auswahl angepasst sind jeweils URL, Page Title, Meta Description, h1 und bei den Farben in gewissem Masse auch die Fliesstexte:
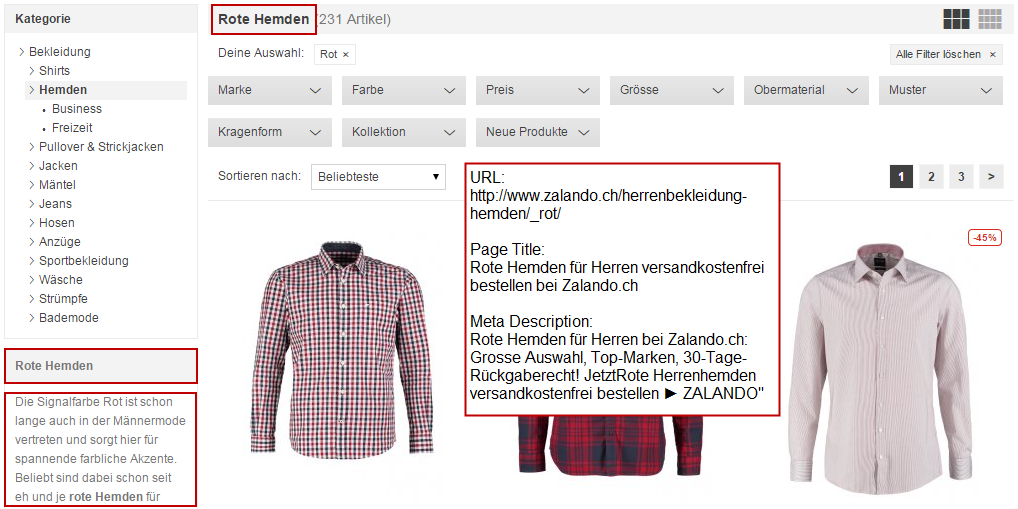
Mit der site-Abfrage bei google.ch ist zu erkennen, dass die Filter-URLs der Marken, Farben und Grössen tatsächlich indexiert werden. Werden jedoch mehrere Filter von Marken, Farbe oder Grösse gewählt, werden nur wenige Filter-URLs der Kombinationen indexiert. Von den übrigen Filtern sind offenbar keine Filter-URLs indexiert.
Anmerkung: Zalando.ch bildet die gewählten Filter in den URLs unterschiedlich ab. Bei nicht relevanten Filtern werden Parameter an die URL angehängt (z.B. “Preis”: www.zalando.ch/herrenbekleidung-hemden/?price_from=26&price_to=120), bei relevanten Filtern wird die URL ohne Parameter ergänzt (z.B. “Farbe”: www.zalando.ch/herrenbekleidung-hemden/_rot/). Im zweiten Fall wird jeweils ein überflüssiges Fragezeichen an die URL angehängt (z.B. www.zalando.ch/herrenbekleidung-hemden/_rot/?), was dann wiederum mittels Canonical-Tag auf die Variante ohne Fragezeichen korrigiert werden muss.
Unterstützende Massnahmen
Folgende Massnahmen unterstützen die oben aufgeführte Steuerung der Indexierung sowie des Crawlings durch Suchmaschinen:
- XML-Sitemap: Die XML-Sitemap darf nur kanonische, aufrufbare, nicht weiterleitende URLs beinhalten. Nicht zu indexierende Filter-URLs haben darin nichts zu suchen.
- Interne Verlinkung: Interne Links aus Texten, der html-Sitemap o.ä. führen so weit möglich nur kanonische URLs auf.
2. Sortieren
Sortierung: Auf Kategorieseiten können Produkte nach gewissen Kriterien wie Preis oder Beliebtheit sortiert werden.
Die Sortierfunktion von zalando.ch:
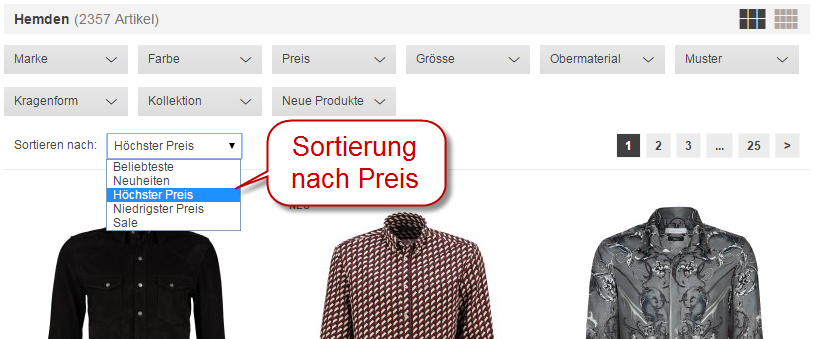
Für jede Sortierung der Kategorieseite “Hemden” besteht eine URL, z.B. für die Sortierung nach “höchster Preis”:
www.zalando.ch/herrenbekleidung-hemden/?order=price
Problematik
In der Regel generiert jedes Umsortieren der Artikel wie beispielhaft aufgeführt weitere Parameter, welche an die URL anhängt werden. Das bedeutet wie bei der Filternavigation diskutiert zahlreiche zusätzliche “Sortier-URLs”, welche identische Inhalte aufweisen und somit Duplicate Content generieren.
Lösung
Sortier-URLs sind von der Indexierung in Suchmaschinen auszuschliessen. Grund: Eine Sortier-URL – also eine anders sortierte Variante der eigentlichen Kategorieseite – bringt weder den Suchenden als Suchergebnis in Google einen zusätzlichen Nutzen, noch vermag sie zusätzliche Keyword-Kombinationen mit relevantem Suchvolumen abzudecken. Die Steuerungsmöglichkeiten für die Nicht-Indexierung sind oben bei “1. Filtern” aufgeführt.
Wie macht’s zalando.ch?
Die Sortierfunktion fügt, wie im obigen Beispiel ersichtlich, Parameter an die URL an. Die so erzeugten URLs werden mittels Canonical-Tag (Verweis auf die URL-Variante ohne die Parameter) von der Indexierung ausgeschlossen.
3. Blättern
Pagination: Weil eine Kategorie zahlreiche Produkte enthält, kann im Sinne der besseren Übersichtlichkeit innerhalb der Kategorie vor und zurück geblättert werden.
Die Pagination von zalando.ch:
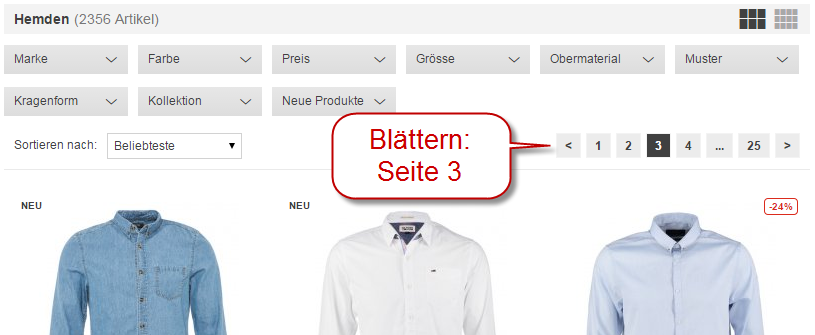
Für jede geblätterte Seite der Kategorie “Hemden” besteht eine URL, z.B. für die dritte Seite:
www.zalando.ch/herrenbekleidung-hemden/?p=3
Problematik
In der Regel generiert jedes Blättern in der Kategorieseite wie beispielhaft aufgeführt Parameter, welche an die URL anhängt werden. Das bedeutet wie oben bei der Facettennavigation und beim Sortieren diskutiert zahlreiche zusätzliche “Blätter-URLs”, welche sehr ähnliche Inhalte aufweisen und somit im schlechtesten Fall Duplicate Content erzeugen. Zudem erkennen die Suchmaschinen womöglich nicht, dass die Blätter-URLs zu einer Serie von URLs resp. derselben Kategorie gehören.
Lösung
Beim Blättern sollte nicht einfach ab der zweiten Seite das Canonical-Tag auf die erste Seite gesetzt werden, denn dabei gingen quasi die individuellen Inhalte der Produkte auf Seiten 2 bis n verloren, da sie wegen des Canonical-Tags nicht indexiert würden.
Es gibt je eine Lösung mit und ohne Übersichtsseite (View-all-Page). Beide werden im Folgenden diskutiert und sind hier schematisch abgebildet:
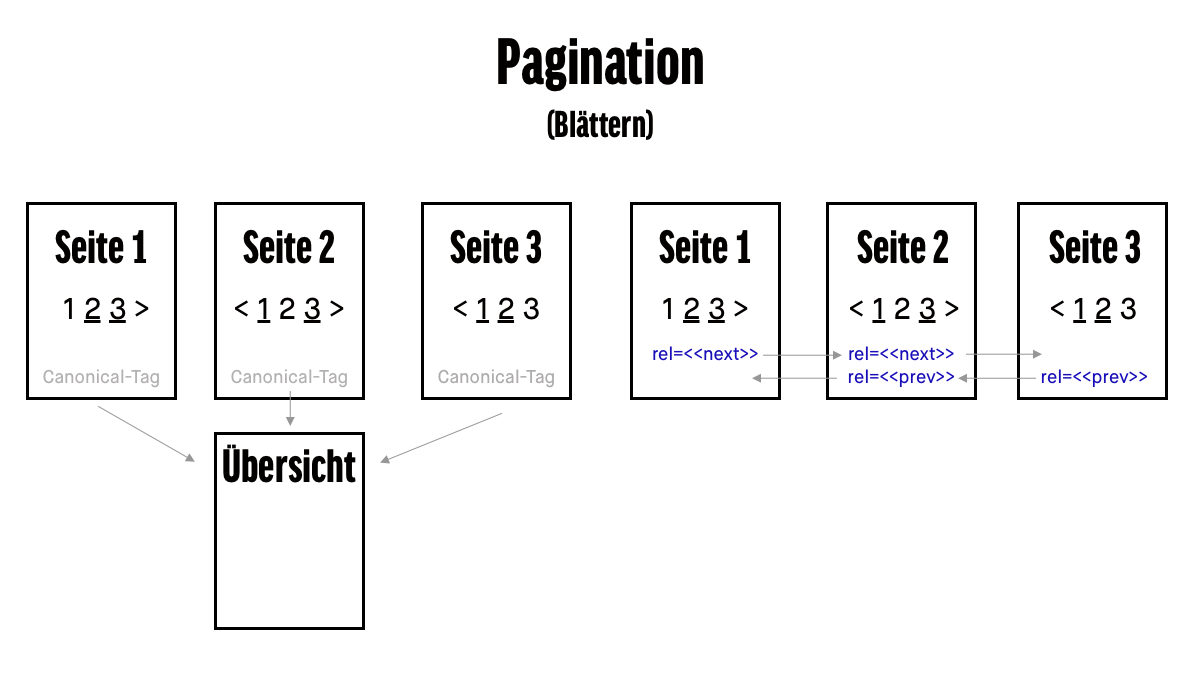
Lösung mit Übersichtsseite
Falls neben den einzelnen Blätter-URLs auch eine Übersichtsseite (eine Seite, auf der alle Produkte der Kategorie aufgeführt sind) der Kategorie existiert und diese beim Aufruf nicht zu lange lädt, sollte gemäss Empfehlung von Google die Übersichtsseite indexiert werden und nicht die einzelnen Blätter-URLs. Dies geschieht, indem auf jeder Blätter-URL das Canonical-Tag auf die Übersichtsseite gesetzt wird. Vorteil: Alle Inhalte werden indexiert und die Backlinks und andere ranking-relevanten Signale werden auf die Übersichtsseite akkumuliert. Das Canonical-Tag verweist auf den Blätter-URLs (beispielhaft) folgendermassen auf eine Übersichtsseite:
<link href=”http://www.zalando.ch/herrenbekleidung-hemden/uebersicht/” rel=”canonical” />
Lösung ohne Übersichtsseite
Falls keine Übersichtsseite existiert oder diese nicht indexiert werden soll, kommen die Tags rel=”next” und rel=”prev” zum Einsatz. Diese weisen den Suchmaschinen den Zusammenhang der geblätterten Seiten auf, akkumulieren die ranking-relevanten Signale aller Blätter-URLs der Kategorie und spielen als Suchergebnis in der Regel Seite 1 der geblätterten Sequenz aus. Dabei werden aber alle Inhalte der geblätterten Sequenz indexiert (im Unterschied zum Einsatz des Canonical-Tags). Die Tags werden im des Quelltextes platziert, jede Blätter-URL verweist dabei auf die vorherige Seite mit dem rel=”prev” und auf die folgende Seite mit dem rel=”next”. Einzig die erste und letzte Seite weisen entsprechend nur das eine benötigte Tag auf. Für die Seite www. zalando. ch /herrenbekleidun … würden die Tags folgendermassen lauten:
<link href=”http://www.zalando.ch/herrenbekleidung-hemden/?p=2″ rel=”prev” />
<link href=”http://www.zalando.ch/herrenbekleidung-hemden/?p=4″ rel=”next” />
Wie macht’s zalando.ch?
Zalando.ch verfährt nicht gemäss Best Practice: Es werden zwar wie für die “Lösung ohne Übersichtsseite” beschrieben die rel=”next” und rel=”prev” eingesetzt. Gleichzeitig ist aber auch ein Canonical-Tag im Quelltext eingebunden, welches auf die Seite 1 (also jene ohne Blätter-Parameter) der Kategorie verweist. Das Canonical-Tag übersteuert rel=”next” und rel=”prev”, sodass die Blätter-URLs nicht im Index von Google zu finden sind. Warum zalando.ch so vorgeht, ist von aussen nicht ersichtlich. Ein möglicher (beabsichtigter oder unbeabsichtigter) Grund könnte sein, dass das Canonical-Tag fix in den Quelltext implementiert ist, sobald ein “?” in der URL auftaucht, weil beim Filtern und Sortieren auf diese Weise die parametrisierten URLs von der Indexierung ausgeschlossen werden (siehe auch Anmerkung bei “Wie machts zalando.ch?” im Kapitel “1. Filtern”).
Fazit
Zugegeben: Die hier diskutierte Thematik ist etwas trocken und einigermassen komplex – erst recht, wenn es um die kombinierte Betrachtung der drei Funktionen geht! Aber aus Sicht der Suchmaschinenoptimierung sind die Hebel beim Filtern, Sortieren und Blättern von Kategorieseiten enorm. Daher lohnt sich eine vertiefte Auseinandersetzung alleweil. Es locken: aufgeräumtere Google-Indices, entlastete Serverinfrastrukturen, sinnvoller eingesetzte Crawling-Budgets der Suchmaschinen, breitere und bessere Rankings und damit mehr Shop-Besucher sowie Umsatz – und folglich zufriedene Auftraggeber:innen.
Mehr Artikel?
Alle Artikel ansehen


Fragen?
Head of SEO