


Der dritte und letzte Teil unserer Serie zur internen Verlinkung befasst sich mit einer Reihe von Spezialfällen, die insbesondere für E-Commerce-Betreiber:innen interessant sind. Konkret geht es um eine Besonderheit auf Kategorieseiten bei Online-Shops, Siloing in der Primärnavigation und Linkmaskierung.
Falls Sie Teil 1 und 2 der Serie verpasst habt:
Hier geht es zu den Grundlagen und Kennzahlen der internen Verlinkung.
Hier geht es zu den Tools und Anwendungsfällen.
1. Alle Detailseiten auf Kategorie-Ebene verfügbar machen
Problem:
Bei Online-Shops und auch bei Rezept-Anbietern wird auf Kategorie-Ebene häufig das sog. «Endless Scrolling» eingesetzt (auch als «Infinite Scrolling» bezeichnet). Das heisst, es gibt auf den Kategorieseiten keine Seitenblätterung (Paginierung) über Links wie «2», «3» …, sondern es werden weitere Produkte bzw. Rezepte via AJAX nachgeladen, sobald ein:e Nutzer:in an das Seitenende scrollt oder auf einen Button klickt («Weitere Produkte» o.ä.).
Aus SEO-Sicht ist «Endless Scrolling» problematisch, da bei initialem Page Load nicht alle Links zu den Detailseiten im DOM (= «Document Object Model»; bezeichnet die komplett geladene Baumstruktur einer Seite) hinterlegt sind. Es sollten jedoch alle Detailseiten in möglichst wenigen Schritten intern erreichbar sein, um die Indexierung dieser Seiten zu gewährleisten und eine optimale Weitergabe von Linkjuice sicherzustellen.
Hier bieten sich zwei Lösungsmöglichkeiten an:
Variante 1:
Einbau einer Paginierung mit rel=”prev” und rel=”next”. Dazu ein Praxisbeispiel von Jumbo (siehe rel=”next”-Link im <head>, rot umrahmt im Screenshot).
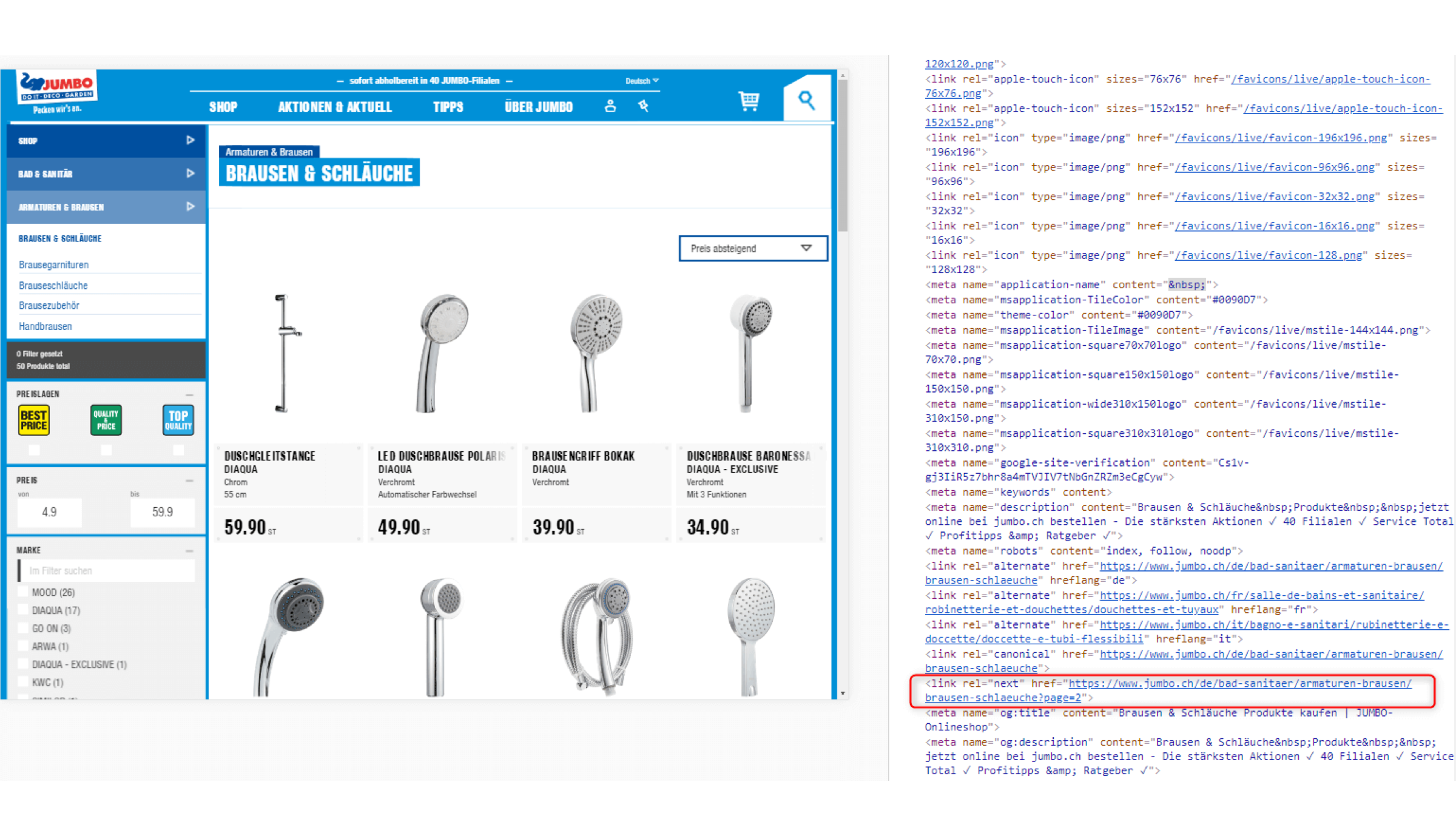
Für Suchmaschinen werden paginierte Seiten geschaffen, auf denen dann die übrigen Detailseiten gelistet sind. Für die Nutzer:innen sind diese paginierten Seiten jedoch nicht erreichbar. Denn: Die Seiten sind nur über die Paginierung im <head> des HTML-Seitenquelltextes aufrufbar, jedoch nicht im sichtbaren Bereich der Nutzer:innen verlinkt.
Tipp: Lesenswert ist in diesem Zusammenhang auch folgender Artikel aus dem Google Webmaster Central Blog, indem eine vergleichbare Lösung vorschlagen wird.
Variante 2:
Auf Kategorie-Ebene wird ein Link hinterlegt, der zu einer Gesamtübersicht aller Produkte in dieser Kategorie führt, wie man z.B. bei melectronics erkennen kann.
Hier ist der Button «36 weitere Ergebnisse anzeigen» im nicht-gerenderten HTML-Seitenquelltext verlinkt: <a class=”…” href=”…?viewAll”>36 weitere Ergebnisse anzeigen</a>
Für die Nutzer:innen wird der Link auf dem Button mit JavaScript übersteuert – das heisst, den Nutzer:innen wird das gerenderte HTML ausgespielt, sodass sie den Link nicht sehen. Für Suchmaschinen ist der Link jedoch problemlos bei initialem Page Load auslesbar.
Unter dieser URL finden die Suchmaschinen alle Produkte in der jeweiligen Kategorie. Gleichzeitig besitzt die View-All-Page einen Canonical Tag, der auf die Ausgangs-Kategorie zeigt. Dadurch ist sichergestellt, dass kein Duplicate Content entsteht und nur die kanonische Kategorie-URL indexiert wird.
2. Siloing in der Primärnavigation
Ganz allgemein gesagt, bezeichnet Siloing die gezielte Abgrenzung einzelner Themenbereiche innerhalb einer Website. Die verschiedenen Themengebiete ergeben sich z.B. aus der Navigationsstruktur.
Die Technik des Siloing sorgt für eine Reduzierung Themen-fremder Verlinkungen auf den Seiten. Es handelt sich also um eine thematische Fokussierung, wodurch die Relevanz und Autorität einzelner Teilbereiche einer Website gestärkt werden.
Je nachdem, wie die Nutzer:innen die Primärnavigation bedienen können, gibt es zwei Siloing-Ansätze:
Variante 1: Siloing ohne JavaScript
Voraussetzung hierfür: Die Menüpunkte der Navigation lassen sich per Mausklick öffnen und schliessen.
Praxisbeispiel Zalando:
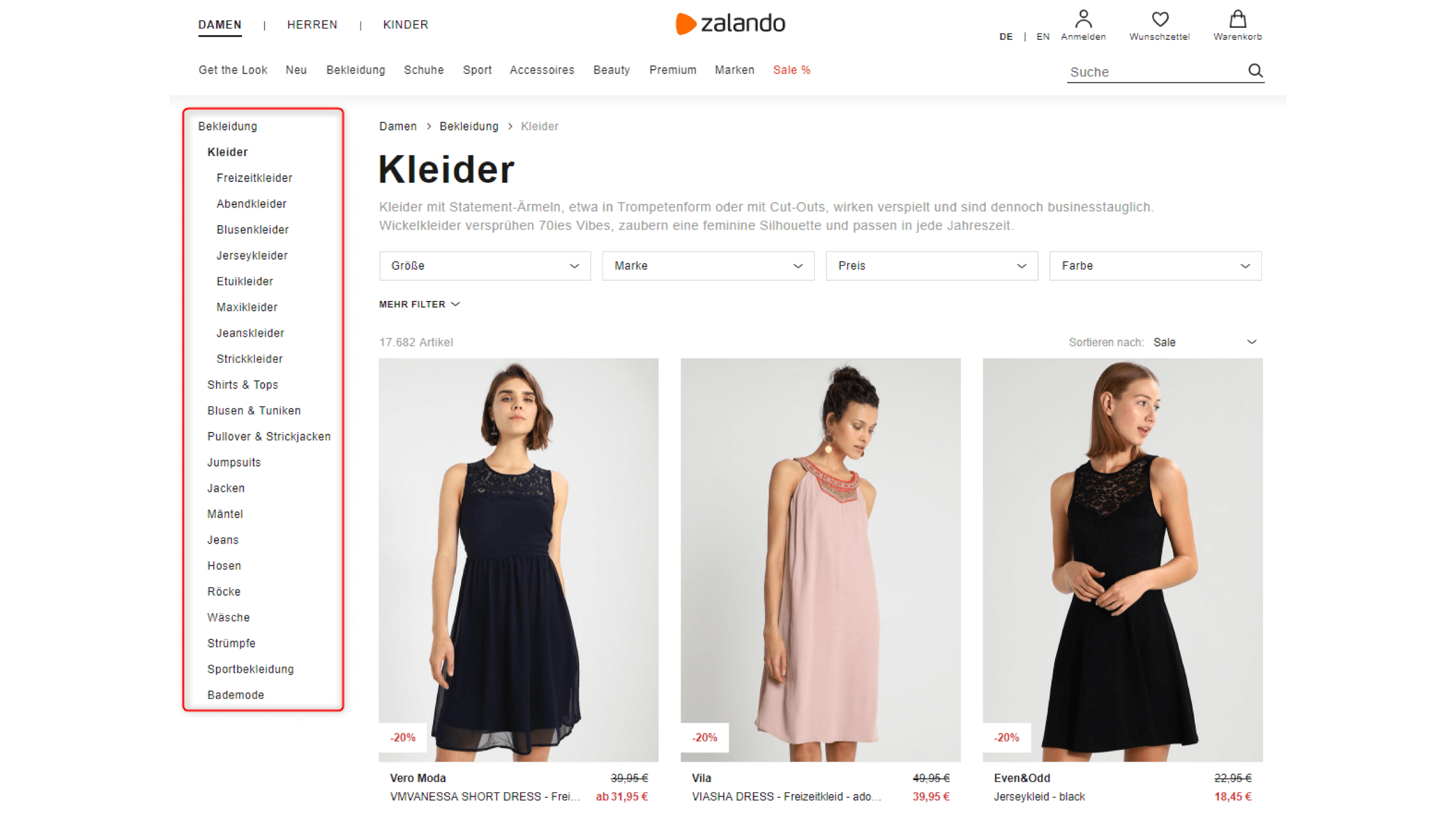
Wenn man sich hier die Navigation am linken Seitenrand anschaut (rot umrahmt im Screenshot) und z.B. auf «Kleider» klickt, fällt Folgendes auf:
- Sobald man in einen Bereich hinein navigiert, wird nur dieser Bereich und dessen Verlinkungen verfügbar gemacht. Die jeweiligen Unterkategorien weisen also nur Links im selben Bereich des Seitenbaums aus. Beispiel: Das Untermenü im Bereich «Kleider» («Freizeitkleider», «Abendkleider» usw.) ist nur dann für die Nutzer:innen anklickbar und im Seitenquelltext hinterlegt, wenn auch tatsächlich auf «Kleider» geklickt wurde. Wenn die Nutzer:innen auf einen anderen Bereich klicken (z.B. «Shirts & Tops»), dann findet ein Page Load statt und der Bereich «Kleider» wird eingeklappt. Im Seitenquelltext ist dann zwar noch der Link «Kleider» hinterlegt, aber nicht mehr das Untermenü zu «Kleider». Stattdessen ist nun das von den Nutzer:innen angeklickte Untermenü verfügbar.
- Diese Logik funktioniert übrigens auch bei deaktiviertem JavaScript. Somit können Suchmaschinen problemlos alle Navigationslinks aufrufen und auslesen.
Variante 2: Siloing mittels JavaScript
Visualisierungen komplexer interner Linkstrukturen sind übrigens miVoraussetzung hierfür: Das Öffnen der Untermenüs in der Navigation funktioniert per mouse-over.
- Sobald die Nutzer:innen in einen Bereich hinein navigieren, wird der Suchmaschine lediglich die nächste Ebene der Navigation innerhalb des gewählten Navigationspfades zur Verfügung gestellt sowie die Links auf Level 1. Die Links der anderen Unterbereiche werden per JavaScript via mouse-over dynamisch nachgeladen.
- Auf diese Weise wird – ähnlich wie beim ersten Siloing-Ansatz – die Anzahl Links pro Seite reduziert, was zu einer Stärkung der verbleibenden Links führt.
- Für die Nutzer:innen ist das Siloing in diesem Fall nicht sichtbar. Sie können wie gewohnt per mouse-over das Menü bedienen.
Übrigens: Bei beiden Varianten verstärkt sich der Siloing-Effekt zusätzlich, wenn innerhalb eines Themenbereichs sinnvolle Querverlinkungen zu verwandten Seiten gesetzt werden.
Wer mehr zum Thema Siloing wissen möchte, dem oder der sei dieser Artikel empfohlen.
3. Linkmaskierung mit dem PRG-Pattern
Bei Online-Shops mit unterschiedlichen Filter- und Sortiermöglichkeiten entstehen häufig sehr viele Unterseiten, die das Crawl-Budget unnötig belasten können. Ursache hierfür sind Parameter-URLs mit zumeist unzähligen Ausprägungen, Kombinationen und Reihenfolgen. Eine wirksame Möglichkeit, um dieses Problem zu lösen, besteht in der Maskierung interner Links auf Kategorie-Ebene. Ziel: Der Crawler soll nur denjenigen Links folgen, die für das organische Ranking relevant sind. Alle andere Links in der Filternavigation sollen ignoriert werden.
Die technisch sinnvollste Methode der Linkmaskierung ist aus SEO-Sicht das sogenannte PRG-Pattern. PRG steht für POST-Redirect-GET. Neben der gezielten Crawling-Steuerung hat das PRG-Pattern den grossen Vorteil, dass der Linkjuice besser verteilt wird, denn die maskierten Links sind für Suchmaschinen nicht mehr sichtbar.
Konkret geht es um Folgendes:
- Bei der Auswahl einer Filterkombination durch Aufruf eines Links wird zunächst ein POST-Request an den Server übermittelt und in der Datenbank verarbeitet. Im Fall eines Online-Shops wird an dieser Stelle geklärt, welche Produkte aufgrund der gewählten Filterkombination ausgespielt werden sollen. Die Informationen werden in einer Cookie-basierten Session gespeichert.
- Doch anstatt die Ergebnisseite nun direkt anzuzeigen, erfolgt ein Redirect und der POST-Befehl wird in ein GET umgewandelt, wodurch sich die Darstellung des Webseiten-Inhalts verändert, ohne dass jedoch eine neue URL erzeugt wird.
Ein Code-Beispiel zum PRG-Pattern gibt es hier.
Das PRG-Pattern lässt sich auch bei Flyout-Navigationen und Footer-Links einsetzen, um Links, die für das organische Ranking nicht relevant sind, bewusst zu maskieren.
Alle Vorteile dieser Methode im Überblick:
- Suchmaschinen können dem POST in der Regel nicht folgen, wodurch das Crawling effektiv geschont wird. Die Effekte können z.B. in den Logfiles nachvollzogen werden.
- Die Nutzer:innen merken von diesem Vorgang grundsätzlich nichts und können die Filter im Online-Shop ganz normal bedienen.
- Der vorhandene Linkjuice wird durch die Linkmaskierungen gezielt auf die wirklich wichtigen Seiten gelenkt.
Nachteile:
- Der technische Implementierungsaufwand ist hoch, da das PRG-Pattern immer individuell eingefügt werden muss und es je nach Server-Technologie oder CMS zu zusätzlichen Hürden kommen kann.
- Durch das PRG-Pattern entstehen erst einmal keine neuen URLs, sodass die Nutzer:innen das Filter-Ergebnis nicht bookmarken oder teilen können. Dieser Nachteil lässt sich durch den Einsatz von Hashtags-URLs bzw. Sprungmarken-URLs lösen.
Wichtig bei der Implementierung:
- Die alten, nicht SEO-relevanten Filter-URLs sollten de-indexiert werden.
- Variante 1: Wenn man wie oben beschrieben Hashtags-URLs einsetzt, dann lassen sich am besten 301-Redirects von den alten URLs zu den Hashtags-URLs einrichten.
- Variante 2: Wenn man keine Hashtags-URLs einsetzt, dann sollten die alten URLs jeweils mit einem Status Code 410 («Gone») versehen werden.
- Bevor das PRG-Pattern live geht, sollte es zusätzlich ein Indexierungsmanagement geben (z.B. via Canonical Tag oder Meta Tag Robots “noindex”).
Alternativen zum PRG-Pattern (= Steuerung des Crawlings):
- Interne Links mit rel=”nofollow” auszeichnen. Dadurch wird jedoch kein Linkjuice eingespart, sondern nur die Weitergabe unterbrochen. Siehe hierzu folgendes Google-Video.
- In vielen Fällen (wenn beispielsweise Parameter-URLs vorliegen) lassen sich auch einfach Crawling-Ausschlüsse via robots.txt vornehmen, was im Vergleich zum PRG-Pattern wesentlich schneller umgesetzt werden kann. Allerdings wird wie bei der ersten Alternative kein Linkjuice eingespart.
- URL-Parameter in der Google Search Console einrichten. Nachteile: Diese Konfiguration wird nur vom Google Bot berücksichtigt («Insel-Lösung»). Zudem erfolgt auch hier keine Linkjuice-Steuerung.
Weitere Hintergrund-Infos zum PRG-Patterns gibt es in diesem Artikel.
Mehr Artikel?
Alle Artikel ansehen


Fragen?
Head of SEO